elasticsearch是一个基于Lucene的分布式搜索引擎,能够支持准实时的数据检索NRT(near real-time),支持海量数据的处理,包括结构化和非结构化数据,提供强大的全文搜索能力,但是ES不仅仅是一个全文搜索引擎,他能够解决传统数据库解决不了的复杂查询,计算,聚合等操作,还有时序数据的处理,比如日志处理、监控数据的存储、分析和可视化等
总体结构
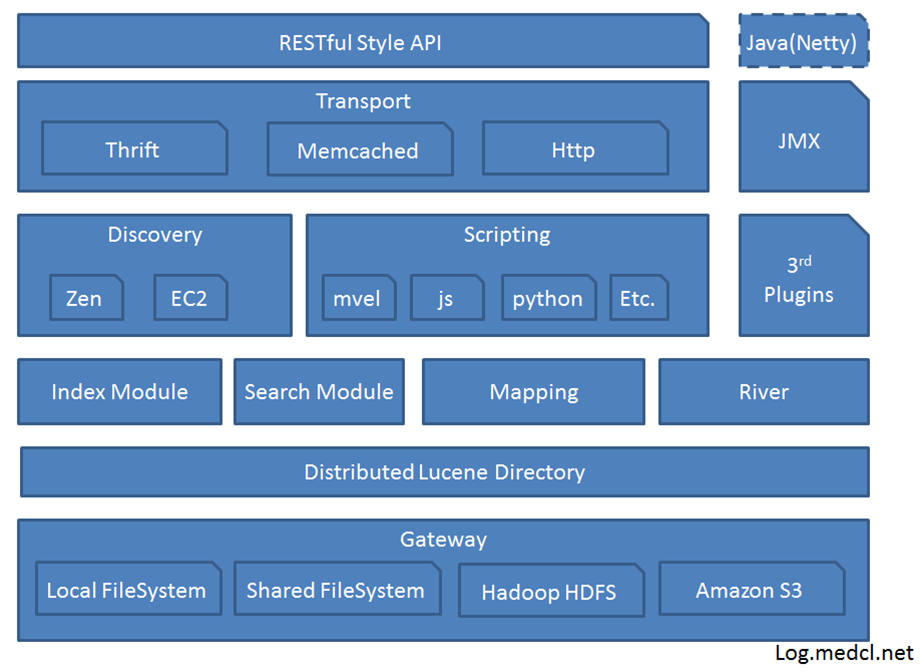
1: Gateway是ES用来存储索引的文件系统,支持多种类型。包括本地文件系统(默认),HDFS,S3等
2: Distributed Lucene Directory是一个分布式的lucene框架
3: Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
4: ES模块之上是 Discovery、Scripting和第三方插件
5: Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。
6: Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。ES也支持多种第三方插件。预先定义好脚本内容,然后在mapping阶段或者search指定需要的脚本,相对于脚本语句查询来说提高性能
7: 再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用。
8: 最上层是ES提供给用户的接口,可以通过RESTful接口或java api和ES集群进行交互
集群模式
elasticsearch集群实现介于P2P和master-slave的方式,具体有以下几种节点类型
Master-eligible node
Master节点用于管理和控制Elasticsearch集群,并负责在集群范围内创建删除索引,跟踪哪些节点是集群的一部分,并将分片分配给这些节点。主节点一次处理一个集群状态,并将状态广播到所有其他节点,这些节点需要响应并确认主节点的信息。
node.master=true 表示该节点有资格成为master节点
Data node
数据节点保存数据并执行与数据相关的操作,如CRUD、搜索和聚合,默认情况下,node.data=true,表示每个节点都为一个data节点,如果您想要一个专用的master节点,那么将node.data属性更改为false。通常在大型的集群这么做,master只做控制节点
node.data=true 表示该节点为data节点,默认为true
Ingest node
摄取节点(或者预处理节点)能够在索引操作之前对document进行增强或者丰富等预处理操作,默认node.ingest: true
预处理类似于ETL操作,该操作发生在bulk和index之前,通过pipeline和processor的方式实现,非常类似于logstash的filter,但它应该是elasticsearch锦上添花的能力,对于多源头,复杂的,量大的操作还是需要logstash来完成
Tribe node
Tribe node是一种特殊的coordinating node,它可以连接到多个集群,并在多个集群上执行搜索或者其他操作,对于涉及到多个集群之间的查询,可以使用tribel node的方式, 但是tribel node是以coordinating node的方式加入到各个集群中,master的变更任务必须要等Tribe node的返回,tribe的问题显而易见, 所以elasticsearch在高版本引入了Cross Cluster Search
coordinating node
所有节点默认为coordinating node,并且不可以关闭,该节点作为负载路由器,将传入的请求路由到集群中的不同节点。coordinating node节点处理客户端的请求一般分为两个阶段,第一节点,收到客户端的请求并路由到合适的分片(包含请求数据的主分片),第二阶段对结果做聚合1
2
3
4
5
6cluster.routing.allocation.enable
all - (默认值)允许为所有类型的分片分配分片。
primaries - 仅允许分配主分片的分片。
new_primaries - 仅允许为新索引的主分片分配分片。
none - 任何索引都不允许任何类型的分片。
`
Allocation & Rebalancing

Allocation
Allocation是指将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。
Allocation操作发生在故障恢复,副本分配,Rebalancing,节点的新增和删除等场景,master节点的主要职责就是决定分片分配到哪一个节点,并且做分片的迁移来平衡集群
Shard allocation filters
allocation filters允许执行分片分配之前,前置一些filter操作,可以基于_name, _host_ip, _publish_ip, _ip, _host and _id 等属性,例如计划下线一个node,可以设置不允许给该node分配分片:1
2
3
4
5
6PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
disk-based shard allocation
es在进行shard allocation的时候,会充分考虑每一个node的可用磁盘空间,具体有如下配置:
1: cluster.routing.allocation.disk.threshold_enabled:默认是true,如果是false会禁用基于disk的考虑
2: cluster.routing.allocation.disk.watermark.low:控制磁盘使用率的低水位,默认是85%,如果一个节点的磁盘空间使用率已经超过了85%,那么就不会分配shard给这个node了
3: cluster.routing.allocation.disk.watermark.high:控制磁盘使用率的高水位,默认是90%,如果一个节点的磁盘空间使用率已经超过90%了,那么就会将这个node上的部分shard移动走
4: cluster.info.update.interval:es检查集群中每个node的磁盘使用率的时间间隔,默认是30s
5: cluster.routing.allocation.disk.include_relocations:默认是true,意味着es在计算一个node的磁盘使用率的时候,会考虑正在分配给这个node的shard。
Rebalancing
1 | cluster.routing.rebalance.enable |
1 | cluster.routing.allocation.allow_rebalance |
1 | cluster.routing.allocation.cluster_concurrent_rebalance |
路由规则
协调节点(coordinating node)通过文档id的hash值(murmur3散列函数)和主分片数量(Primary shard)取模,确定文档应被索引到哪个分片。shard = hash(document_id) % (num_of_primary_shards)
高可用
cluster stat
es集群的高可用通过cluster stat来实现,cluster state是全局性信息, 包含了整个群集中所有分片的元信息(规则,位置, 大小等信息), 并保持每个每节的信息同步。cluster state是由ES的master节点维护的(只有主节点能够改变集群状态), 当它收到data节点的状态更新变化后, 就把这些信息依次广播到其他节点,同步集群状态的时候,ES会做些额外的处理:只有变化的cluster state信息才会被广播,在cluster state传递之前或做些压缩
具体的过程如下所示:
1: 主节点处理一个改变的集群状态,并将改变的状态publish给所有的其他节点。
2: 其他节点收到主节点publish的message,向主节点确认收到信息(acknowledge。 it),但不将改变同步到本地的集群状态(not applay it)
3: 如果主节点在配置的时间(discovery.zen.commit_timeout 默认30s)没有收到指定个数节点(discovery.zen.minimum_master_nodes)的确认信息,那么该改变的状态就会被rejected。
4: 如果主节点在指定的时间内收到了指定个数节点的确认信息,则会提交(commit)该状态的改变,并向其他的节点发送该改变。
5: 其他的节点收到信息后,则应用该改变到本地的集群状态中,应用后向主节点发送应用成功信息。
6: 主节点等待所有节点的发送的应用成功消息,直到超时(discovery.zen.publish_timeout 默认30s)。
节点加入与离开
节点加入
当一个新节点加入的时候,它通过discovery.zen.ping.unicast.hosts配置的节点获取集群状态,然后找到master节点,并向其发送一个join request(discovery.zen.join_timeout)。主节点接收到reqest后,同步集群状态到新节点。
非主节点节点离开
当一个节点出现3次ping不通的情况时(ping_interval 默认为1s;ping_timeout 默认为30s),主节点会认为该节点已宕机,将该节点踢出集群。
主节点离开
当主节点发生故障时,集群中的其他节点将会ping当前的master eligible 节点,并从中选出一个新的主节点。
选主过程
- 节点启动之后,从配置文件获取集群列表,discovery.zen.ping.unicast.hosts: [“host1”, “host2”]
- Ping的response会包含该节点的基本信息以及该节点认为的master节点,先从各节点认为的master中选,按照节点id排序,取第一个。
- 如果各节点都没有认为的master,则从所有节点中选择,规则同上。
- 通过discovery.zen.minimum_master_nodes这个参数设置为(N/2)+1,避免因为网络分区而产生脑裂。
NRT(near real-time)
es的准实时在于在写入数据的时候,采用内存buff+文件系统缓存+磁盘三级结构,确保写入的数据能够近实时的被检索到,整个过程如下
- 新收到的数据存放于内存buff中,同时将数据写入translog日志文件,这个时候是检索不到的
- 数据从内存buff刷新到文件系统缓存中(OS cache),refresh默认1s,生成一个新的segment,清空内存数据,这个时候可以被检索到了
- 默认每隔30分钟或者translog大于512MB,执行一个flush操作,首先将commit point写入磁盘文件,标识这个commit point对应的所有的segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。最后清空现有translog日志文件,重启一个translog,此时commit操作完成。
数据一致性
- ES的数据写入一致性由translog保证
- translog文件本身也是先写os cache,然后再刷到磁盘的,默认5s,如果宕机,可能会有5s的数据都是,当然不如不考虑性能的影响,可以设置每次写操作都刷到磁盘吗
- 副本一致性则采用半同步的方式,即主分片写入之后,只要一定数量副分片返回写入成功,则返回客户端成功,wait_for_active_shards的默认值为int( (primary + number_of_replicas) / 2 ) + 1